

Чтобы не утонуть в видах тестов, держите набор компактным и риск-ориентированным: разделите проверки по уровням (юнит/интеграция/система/приёмка), выберите критичные пользовательские потоки и риски, автоматизируйте только стабильные сценарии, а остальное оставьте на быстрые ручные сессии и мониторинг. Так тестирование программного обеспечения становится управляемым и предсказуемым.
Что важно помнить при выборе наборов тестов
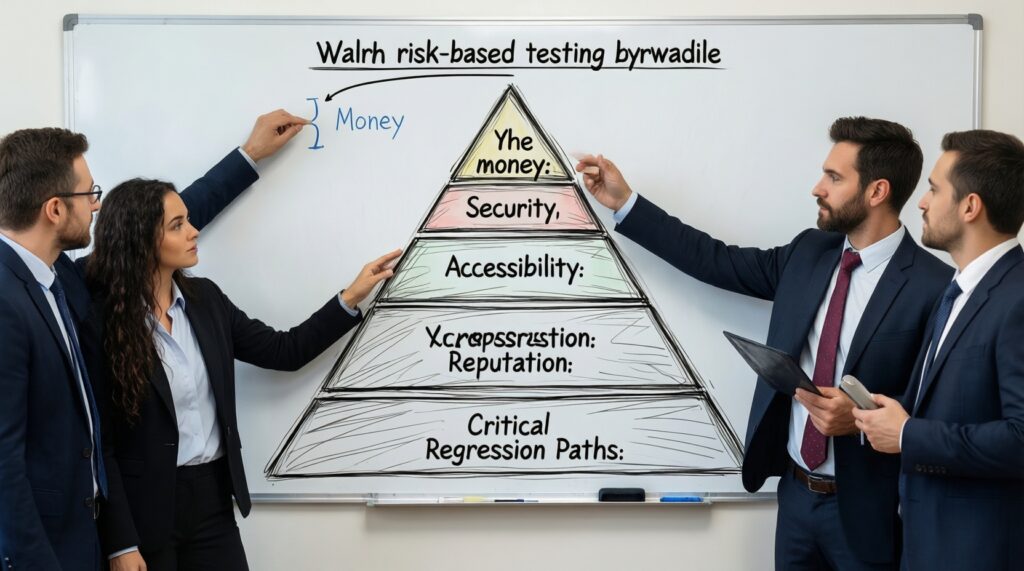
- Начинайте не с полного покрытия, а с рисков: деньги, безопасность, доступность, репутация, регресс в критичных потоках.
- Чем ближе тест к пользователю, тем он дороже и медленнее; чем ближе к коду, тем быстрее обратная связь.
- Автоматизируйте то, что часто повторяется и стабильно; "хрупкие" UI-сценарии автоматизируйте выборочно.
- Поддержка тестов - такая же работа, как разработка: планируйте время на рефакторинг тестов и данных.
- Набор тестов должен быть "воротами релиза": понятные критерии, кто и как принимает решение о выпуске.
Классификация тестов: от юнитов до приёмочных
Ниже - практичная классификация, чтобы выбрать минимум нужного и не раздувать матрицу. В контексте "услуги тестирования ПО" это также помогает формулировать задачу подрядчику: что именно проверять и на каком уровне.
| Тип теста | Цель | Относительная стоимость | Рекомендуемая частота | Когда не стоит делать |
|---|---|---|---|---|
| Юнит-тесты | Поймать ошибки логики на уровне функций/классов, дать быструю обратную связь | Низкая | На каждый коммит/PR | Если код не тестопригоден и дешевле исправить архитектуру/границы модулей, чем писать "тесты вокруг боли" |
| Интеграционные | Проверить стыки: БД, очереди, внешние сервисы, контракты | Средняя | На PR и в nightly | Если нет изоляции зависимостей и тесты будут флапать из‑за нестабильных окружений |
| Контрактные (consumer/provider) | Зафиксировать договорённости между сервисами, уменьшить регресс при изменениях API | Средняя | При изменениях API + в CI | Если у вас монолит без явных API-границ - сначала выделите интерфейсы |
| Системные / end-to-end | Проверить ключевые пользовательские потоки на "почти проде" | Высокая | Перед релизом + по расписанию | Если тесты проходят через нестабильный UI и дают много ложных падений - оставьте только "дымовые" проверки |
| UI-регресс (авто) | Отловить поломки интерфейса и навигации | Высокая | Для критичных экранов, не для всего сайта/приложения | Если UI часто меняется - автоматизированное тестирование UI будет стоить дороже пользы |
| Приёмочные (UAT) | Подтвердить, что релиз решает задачу бизнеса и корректен по требованиям | Высокая | Перед релизом/по этапам | Если критерии приёмки не определены - сначала согласуйте DoD/acceptance criteria |
Практические советы выбора уровня
- Правило "сдвига влево": старайтесь ловить максимум дефектов юнитами и интеграционными тестами, а e2e оставить как короткий "коридор безопасности".
- Слои по рискам: чем выше ущерб от дефекта, тем больше уровней проверок для конкретного сценария (но не для всей системы).
- Единый словарь: договоритесь в команде, что именно вы называете "интеграционным" и "e2e", иначе набор тестов будет расти хаотично.
Риск-ориентированный подход к покрытию тестами
Цель - не "покрыть всё", а защитить то, что критично. Это снижает общую стоимость тестов и делает понятнее, из чего складывается тестирование ПО цена: вы платите за защиту конкретных рисков, а не за абстрактные проценты покрытия.
Что понадобится заранее
- Карта критичных потоков: 5-15 основных сценариев (регистрация, оплата, оформление, поиск, экспорт, админ‑операции).
- Матрица рисков: вероятность × ущерб, с явным владельцем риска (продукт/техлид/безопасность).
- Доступы и окружения: тестовый стенд, доступ к логам/трейсам, тестовые учётки, возможность подмены внешних зависимостей (моки/стабы).
- Инструменты наблюдаемости: централизованные логи, метрики, алерты, чтобы компенсировать "не написанные тесты" мониторингом.
- Чёткий релизный контракт: что считается блокером, кто принимает решение о выпуске.
Два рабочих шаблона приоритизации
- "Риск → тесты": на каждый риск заведите 1-3 проверки: ранняя (юнит/контракт), средняя (интеграция), поздняя (дымовой e2e).
- "Поток → точки отказа": разберите ключевой поток на шаги и пометьте места, где чаще всего ломается (валидации, права доступа, платежи, интеграции). Тестируйте точки отказа, а не всю комбинационную математику.
Определение минимального набора тестов для релиза
Ниже - безопасная процедура, которая уменьшает избыточность и делает набор тестов воспроизводимым от релиза к релизу.
Риски и ограничения, которые стоит принять до начала
- Полный регресс "всё обо всём" почти всегда проигрывает по стоимости и времени целевому регрессу по рискам.
- Часть дефектов вы поймаете не тестами, а наблюдаемостью и откатом; это нормально, если риск управляем.
- Слишком много e2e приводит к флапам и недоверию к CI; это ухудшает качество быстрее, чем отсутствие пары проверок.
- Если окружения нестабильны, сначала стабилизируйте инфраструктуру тестов, иначе любые метрики "качества" будут шумом.
-
Соберите "релизный дифф". Зафиксируйте, что изменилось: модули, API, миграции БД, конфиги, фичефлаги. Это основа для выбора тестов, а не календарь.
- Добавьте ссылки на PR/тикеты и список затронутых сервисов/пакетов.
- Пометьте изменения, которые трудно откатить (миграции, изменения контрактов).
-
Разметьте критичность по потокам и данным. Сопоставьте изменения с критичными пользовательскими потоками и чувствительными данными (персональные, финансовые, доступы).
- Если поток "деньги/доступ" затронут - обязательны минимум 2 уровня тестов (например, интеграция + дымовой e2e).
-
Сформируйте "минимальный защитный слой". Определите обязательный набор: быстрые юниты, 3-10 дымовых e2e по критичным потокам, несколько интеграционных проверок на изменённые стыки.
- Юниты - для логики и валидаций.
- Интеграция/контракты - для API и внешних зависимостей.
- Дымовые e2e - только "система жива и делает главное".
-
Срежьте комбинации по принципу "одна причина - один тест". Если тесты отличаются только данными, оставьте один параметризованный тест или один сценарий на класс эквивалентности.
- Применяйте классы эквивалентности и граничные значения вместо перебора всех вариантов.
-
Определите ручные сессии как "исследование рисков". Вместо длинного чек-листа ручных проверок запланируйте 2-3 сессии по 30-60 минут на риск-зоны (права, платежи, миграции, производительность).
- Фиксируйте находки как гипотезы → баг/улучшение теста.
-
Задайте релизные ворота и план отката. Опишите, какие падения блокируют релиз, какие допускаются, и какой rollback/feature toggle применяется.
- Без плана отката вы будете пытаться "дотестировать до бесконечности".
- Законсервируйте набор как артефакт. Сохраните список тестов, которые составляют "минимум релиза", и пересматривайте его только при изменении рисков и архитектуры.
Инструменты и автоматизация: где сэкономить время
Автоматизированное тестирование окупается, когда уменьшает повторяемую работу и ускоряет обратную связь. Если вы планируете заказать тестирование ПО у внешней команды, заранее зафиксируйте: какие проверки должны быть в CI, какие - в nightly, какие - вручную.
Как выбирать, что автоматизировать в первую очередь
- Частота × критичность: часто запускаемые проверки по критичным потокам - первые кандидаты.
- Стабильность интерфейсов: API/доменные правила обычно стабильнее UI, поэтому дешевле в поддержке.
- Наблюдаемость как альтернатива: не автоматизируйте редкие сценарии, если их можно надежно "поймать" метриками и алертами.
Чек-лист проверки результата автоматизации
- Тесты детерминированы: повторный запуск даёт тот же результат при тех же входных данных.
- Есть явное разделение: быстрый набор для PR и расширенный для nightly.
- Данные тестов управляемы: фикстуры/сидирование/сброс состояния описаны и воспроизводимы.
- Падение теста даёт диагностируемый сигнал: лог, снимок состояния, понятное сообщение об ожидании/факте.
- Флаки-тесты помечаются и лечатся по SLA команды, а не копятся "в красной зоне" неделями.
- Тесты не зависят от внешней сети без нужды: есть моки/стабы или тестовые контуры.
- Время прогона контролируется: вы знаете, что замедляет пайплайн и что можно вынести в параллель.
- Периодически проводится рефакторинг тестов вместе с кодом, иначе стоимость владения растёт.
Организация тестовой инфраструктуры и параллелизация
Хорошая инфраструктура уменьшает количество "лишних" тестов: когда окружения стабильны и прогон быстрый, проще держать разумный минимум и чаще запускать его. Это особенно важно, если вы используете услуги тестирования ПО и подключаете несколько команд к общим стендам.
Частые ошибки, которые раздувают набор тестов и время прогона
- Один общий стенд на всех без изоляции данных: тесты мешают друг другу, растёт недоверие к результатам.
- Нет стратегии тестовых данных: каждый тест "сам себе создает мир", прогон становится долгим и нестабильным.
- Параллелизация включена без контроля ресурсов: гонки, лимиты БД/очередей, случайные таймауты.
- Секреты и доступы хранятся хаотично: тесты ломаются при ротации ключей и смене окружений.
- Долгоживущие окружения без очистки: накопление мусора, неочевидные зависимости между прогонами.
- Отсутствует контракт на версии: тесты запускаются на не той сборке или против не той схемы БД.
- Внешние интеграции не изолированы: падения сторонних сервисов выглядят как "у нас баг".
- Слишком много e2e на UI: вместо параллелизации вы упираетесь в хрупкость и медленную диагностику.
Два безопасных шага к ускорению
- Эфемерные окружения для PR: поднимайте изолированный контур на ветку/PR, чтобы убрать конфликт данных.
- Шардинг тестов: делите набор на части и запускайте параллельно с закреплением тестов за "шардами" для стабильного времени выполнения.
Метрики и сигналы: как понять, что тестов достаточно
"Достаточно" означает: риски прикрыты на нужной глубине, регресс ловится до пользователя, а пайплайн не тормозит разработку. Метрики полезны, если они ведут к действиям - удалению лишнего, добавлению нужного, стабилизации инфраструктуры.
Рабочие альтернативы "ещё больше тестов"
- Канареечные релизы и фичефлаги - уместны, когда есть быстрый откат и можно ограничить влияние изменений на часть пользователей.
- Контрактное тестирование вместо e2e - уместно в микросервисах, где основные риски в API-стыках, а UI меняется часто.
- Инварианты и property-based подход - уместны для сложной бизнес-логики, где комбинации входов огромны, а правила можно формализовать.
- Наблюдаемость (алерты + SLO) - уместна для редких сценариев и "краёв", когда автоматизация будет дорогой, а сигнал в проде можно надёжно поймать.
Мини-набор сигналов, который стоит отслеживать
- Доля флапающих тестов и время до их исправления.
- Время CI на PR и отдельно время расширенного прогона.
- Тренд дефектов, найденных после релиза, с привязкой к пропущенным рискам/потокам.
- Стабильность окружений: ошибки инфраструктуры отдельно от ошибок продукта.
Типичные опасения инженеров и практические решения
"У нас слишком много тестов, CI стал тормозом" - что делать первым?
Разделите набор на быстрый (PR) и расширенный (nightly), затем вырежьте дубли по принципу "одна причина - один тест". Дальше лечите флаки и параллелизуйте.
Как объяснить бизнесу, почему тестирование ПО цена растёт?
Привяжите затраты к рискам и уровням тестов: какие риски закрываются, какие последствия предотвращаются, какая часть - поддержка существующих тестов. Покажите, что рост вызван изменениями (диффом), а не "желанием тестировать всё".
Когда стоит заказать тестирование ПО у подрядчика, а не делать всё внутри?
Когда нужна быстрая масштабируемость на регресс/приёмку или независимая оценка качества перед релизом. Важно дать подрядчику карту рисков, критерии приёмки и доступ к окружениям/логам.
Автоматизированное тестирование: почему оно "ломается само"?
Чаще всего причина в нестабильных окружениях, плохих тестовых данных или слишком большом количестве UI e2e. Уменьшите долю UI, добавьте контракты/интеграцию и улучшите диагностичность падений.
Нужно ли гнаться за покрытием кода?
Покрытие полезно как индикатор "белых пятен", но не как цель. В риск-ориентированном подходе важнее покрытие критичных сценариев и инвариантов, чем общий процент.
Что делать, если требования меняются каждую неделю и тесты не успевают?
Стабилизируйте минимальный релизный набор вокруг критичных потоков, а изменчивые части проверяйте исследовательскими сессиями. Автоматизируйте только то, что переживает несколько итераций без переделок.
Как понять, что "услуги тестирования ПО" принесли реальную пользу?
Оцените не количество тест-кейсов, а снижение релизных рисков: стабильность релизных ворот, уменьшение дефектов в критичных потоках и улучшение времени обратной связи. Попросите артефакты: матрицу рисков, набор релизных проверок, отчёты о флапах и долгах.

